Paso 1: Definición del Problema
Supongamos que queremos agrupar a los estudiantes
en función de sus patrones de estudio.
Paso 2: Recopilación de Datos
Esta es mi interaccion con google colab
# Datos de estudio (horas de estudio)
datos_estudio = [2, 3, 1, 4, 5, 2.5, 3.5, 4.5]
# No hay salidas en el aprendizaje no supervisado
# Datos de estudio (horas de estudio)
datos_estudio = [2, 3, 1, 4, 5, 2.5, 3.5, 4.5]
# No hay salidas en el aprendizaje no supervisado
Paso 3: Selección de Algoritmo
Elegiremos un algoritmo de clustering como K-Means.
Esta es mi interaccion con google colab
from sklearn.cluster import KMeans
# Crear modelo
modelo_cluster = KMeans(n_clusters=2)
# Entrenar modelo
modelo_cluster.fit([[hora] for hora in datos_estudio])
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
Paso 4: Evaluación del Modelo
Esta es mi interaccion con google colab
# Etiquetas de clúster para cada dato
etiquetas = modelo_cluster.labels_
print("Etiquetas de Clúster:", etiquetas)
DIFERENCIAS CONCEPTUALES:
Aprendizaje Supervisado:
Definición: El modelo se entrena con ejemplos
etiquetados (entradas y salidas conocidas).
- Ejemplos de Algoritmos: Regresión lineal, regresión
logística, máquinas de soporte vectorial.
- Selección: Se utiliza cuando se tiene un
conjunto de datos etiquetado y se desea predecir salidas para nuevas entradas.
Aprendizaje No Supervisado:
-Definición: El modelo se entrena sin ejemplos
etiquetados, buscando patrones o estructuras en los datos.
- Ejemplos de Algoritmos: K-Means, agrupamiento jerárquico,
Análisis de Componentes Principales (PCA).
- Selección: Se utiliza cuando no hay salidas
etiquetadas disponibles y se busca explorar la estructura subyacente de los
datos.
RESUMEN:
- Modelos: En el aprendizaje supervisado, se
entrena un modelo para predecir salidas conocidas. En el no supervisado, se
busca estructuras o patrones en los datos sin salidas conocidas.
- Algoritmos: Los algoritmos de regresión y
clasificación son comunes en el aprendizaje supervisado, mientras que el
agrupamiento y la reducción de dimensionalidad son comunes en el no
supervisado.
- Entrada/Salida: En la programación tradicional, se
proporcionan reglas explícitas. En el aprendizaje automático, se aprenden las
reglas a partir de los datos.
Gráficos de aprendizaje supervisado.
Esta es mi interaccion con google colab
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LinearRegression
# Datos de entrenamiento (horas de estudio, calificaciones)
datos_entrenamiento = [(2, 85), (3, 90), (1, 80), (4, 95), (5, 97)]
# Separar las entradas y salidas
horas_estudio = [x[0] for x in datos_entrenamiento]
calificaciones = [x[1] for x in datos_entrenamiento]
# Crear modelo
modelo = LinearRegression()
# Entrenar modelo
modelo.fit([[hora] for hora in horas_estudio], calificaciones)
# Datos de prueba
datos_prueba = np.arange(1, 6, 0.1)
predicciones = modelo.predict(datos_prueba.reshape(-1, 1))
# Gráfico de datos y regresión lineal
plt.scatter(horas_estudio, calificaciones, label='Datos de Entrenamiento')
plt.plot(datos_prueba, predicciones, label='Regresión Lineal', color='red')
plt.xlabel('Horas de Estudio')
plt.ylabel('Calificaciones')
plt.legend()
plt.title('Aprendizaje Supervisado: Regresión Lineal')
plt.show()
.png)
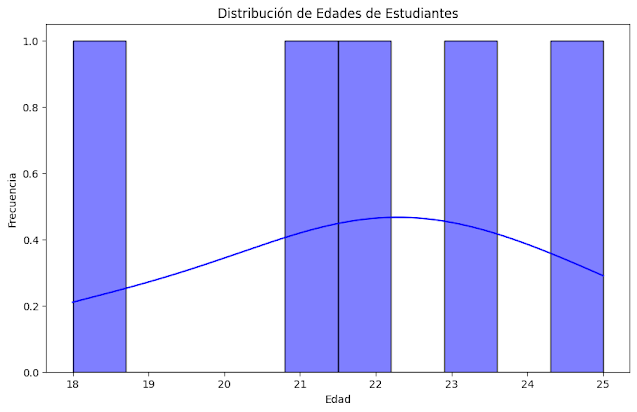
Gráfico de histograma de calificaciones
plt.hist(calificaciones, bins=20, edgecolor='black')
plt.xlabel('Calificaciones')
plt.ylabel('Frecuencia')
plt.title('Histograma de Calificaciones')
plt.show()
Gráficos de aprendizaje no supervisado.
Esta es mi interaccion con google colab
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
# Datos de estudio (horas de estudio)
datos_estudio = [2, 3, 1, 4, 5, 2.5, 3.5, 4.5]
# Crear modelo
modelo_cluster = KMeans(n_clusters=2)
# Entrenar modelo
modelo_cluster.fit([[hora] for hora in datos_estudio])
# Etiquetas de clúster para cada dato
etiquetas = modelo_cluster.labels_
# Gráfico de datos y clústeres
plt.scatter(datos_estudio, [0] * len(datos_estudio), c=etiquetas, cmap='viridis', marker='o')
plt.scatter(modelo_cluster.cluster_centers_, [0] * len(modelo_cluster.cluster_centers_), marker='X', color='red', s=200)
plt.xlabel('Horas de Estudio')
plt.title('Aprendizaje No Supervisado: K-Means Clustering')
plt.show()
import seaborn as sns
# Gráfico de dispersión con colores por cluster
sns.scatterplot(x=datos_estudio, y=[0] * len(datos_estudio), hue=etiquetas, palette='viridis', marker='o')
plt.scatter(modelo_cluster.cluster_centers_, [0] * len(modelo_cluster.cluster_centers_), marker='X', color='red', s=200)
plt.xlabel('Horas de Estudio')
plt.title('Aprendizaje No Supervisado: K-Means Clustering')
plt.show()
Gráfico de Dispersión con Colores por Cluster:
# Calcular la inercia para diferentes números de clústeres
inercia = []
for i in range(1, 6):
modelo_cluster = KMeans(n_clusters=i)
modelo_cluster.fit([[hora] for hora in datos_estudio])
inercia.append(modelo_cluster.inertia_)
# Gráfico de codo
plt.plot(range(1, 6), inercia, marker='o')
plt.xlabel('Número de Clústeres')
plt.ylabel('Inercia')
plt.title('Método del Codo para K-Means')
plt.show()
Diagrama de Codo para Determinar el Número de Clústeres:
# Calcular la inercia para diferentes números de clústeres
inercia = []
for i in range(1, 6):
modelo_cluster = KMeans(n_clusters=i)
modelo_cluster.fit([[hora] for hora in datos_estudio])
inercia.append(modelo_cluster.inertia_)
# Gráfico de codo
plt.plot(range(1, 6), inercia, marker='o')
plt.xlabel('Número de Clústeres')
plt.ylabel('Inercia')
plt.title('Método del Codo para K-Means')
plt.show()
Estos gráficos proporcionan diferentes perspectivas visuales del aprendizaje supervisado y no supervisado. Asegúrate de tener las bibliotecas necesarias instaladas antes de ejecutar los scripts.
Se presenta paso a paso ambos enfoques para un problema de optimización.
Para abordar un problema de optimización, generalmente se busca encontrar los
valores de las variables que minimizan o maximizan una función objetivo, sujeta
a ciertas restricciones. Aquí, proporcionaré un ejemplo simple de optimización
para ambos enfoques: supervisado y no supervisado.
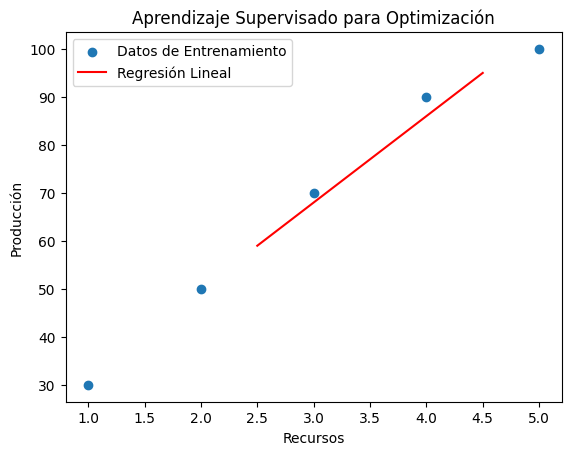
Aprendizaje Supervisado para Problema de
Optimización:
Supongamos que queremos optimizar la producción de una fábrica en función de la cantidad
de recursos utilizados. Tenemos datos históricos que relacionan la cantidad de
recursos (entrada) con la producción (salida).
Paso
1: Definición del Problema
Queremos maximizar la producción utilizando la menor cantidad de recursos posible.
Paso
2: Recopilación de Datos.
Mi interaccion con google colab
import numpy as np
# Datos de entrenamiento (recursos, producción)
datos_entrenamiento = [(2, 50), (3, 70), (1, 30), (4, 90), (5, 100)]
# Separar las entradas y salidas
recursos = np.array([x[0] for x in datos_entrenamiento])
produccion = np.array([x[1] for x in datos_entrenamiento])
Paso 3: Selección de Algoritmo
Elegiremos un algoritmo de clustering como K-Means.
import matplotlib.pyplot as plt
# Datos de prueba
recursos_prueba = np.array([2.5, 3.5, 4.5])
# Realizar predicciones
produccion_predicha = modelo.predict(recursos_prueba.reshape(-1, 1))
# Gráfico de regresión
plt.scatter(recursos, produccion, label='Datos de Entrenamiento')
plt.plot(recursos_prueba, produccion_predicha, label='Regresión Lineal', color='red')
plt.xlabel('Recursos')
plt.ylabel('Producción')
plt.legend()
plt.title('Aprendizaje Supervisado para Optimización')
plt.show()
import seaborn as sns
# Etiquetas de clúster para cada dato
etiquetas_cluster = modelo_cluster.labels_
# Gráfico de dispersión con colores por clúster
sns.scatterplot(x=datos_produccion[:, 0], y=datos_produccion[:, 1], hue=etiquetas_cluster, palette='viridis', marker='o')
plt.scatter(modelo_cluster.cluster_centers_[:, 0], modelo_cluster.cluster_centers_[:, 1], marker='X', color='red', s=200)
plt.xlabel('Característica 1')
plt.ylabel('Característica 2')
plt.title('Aprendizaje No Supervisado para Optimización')
plt.show()
Estos scripts generan diferentes tipos de gráficos para visualizar los resultados de
los enfoques de aprendizaje supervisado y no supervisado en problemas de optimización. Asegúrate de tener las bibliotecas necesarias instaladas
(`numpy`, `matplotlib`, `scikit-learn`, `seaborn`).
Ejemplo de regresión lineal para predecir las calificaciones de los estudiantes en función de las horas de estudio. Incluiré la creación de
datos, la visualización de la regresión lineal y la predicción de calificaciones.
Esta es mi interaccion con google colab
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# Crear datos de ejemplo
np.random.seed(42)
horas_estudio = np.random.uniform(1, 5, 20)
calificaciones = 75 + 10 * horas_estudio + np.random.normal(0, 5, 20)
# Visualizar datos
plt.scatter(horas_estudio, calificaciones, label='Datos de Estudio')
plt.xlabel('Horas de Estudio')
plt.ylabel('Calificaciones')
plt.title('Datos de Estudio y Calificaciones')
plt.legend()
plt.show()
# Crear y entrenar el modelo de regresión lineal
modelo_regresion = LinearRegression()
modelo_regresion.fit(horas_estudio.reshape(-1, 1), calificaciones)
# Visualizar la regresión lineal
plt.scatter(horas_estudio, calificaciones, label='Datos de Estudio')
plt.plot(horas_estudio, modelo_regresion.predict(horas_estudio.reshape(-1, 1)), color='red', label='Regresión Lineal')
plt.xlabel('Horas de Estudio')
plt.ylabel('Calificaciones')
plt.title('Regresión Lineal para Predecir Calificaciones')
plt.legend()
plt.show()
# Hacer predicciones
horas_estudio_nuevas = np.array([2.5, 3.5, 4.5]).reshape(-1, 1)
predicciones = modelo_regresion.predict(horas_estudio_nuevas)
print("Predicciones para nuevas horas de estudio:", predicciones)
.png)
.png)
Este script crea datos de ejemplo, utiliza regresión lineal para modelar la
relación entre las horas de estudio y las calificaciones, visualiza los datos y la regresión lineal, y realiza predicciones para nuevas horas de
estudio. Asegúrate de tener la biblioteca `matplotlib` instalada antes de
ejecutar el script.
Conclusiones y reflexiones: Es muy importante conocer la diferencia entre el
Aprendizaje Supervisado y aprendizaje No Supervisado, más
los fundamentos teóricos proporcionados.
La visualizacion de estos ejemplos con seguridad me enseñaran a mejorar en el
verdadero significado del aprendizaje con mis estudiantes.
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)

Comentarios
Publicar un comentario