COMPONENTES DEL PENSAMIENTO COMPUTACIONAL PARA DESARROLLAR UN EJEMPLO EN EDUCACION SUPERIOR CON PYTHON
DIPLOMADO EN INTELIGENCIA ARTIFICIAL
MODULO IV
APRENDIZAJE AUTOMATICO CON PYTHON Y ASISTENTES INTELIGENTES
Ortega Irusta Elsy Nilda
Este es el chat GPT
https://chat.openai.com/c/111ac8ca-4cd2-4468-8904-fff3a93cdbdc
COMPONENTES DEL PENSAMIENTO COMPUTACIONAL PARA DESARROLLAR UN
EJEMPLO EN EDUCACION SUPERIOR CON PYTHON
El pensamiento computacional es una habilidad fundamental
en ciencias de la computación que involucra diferentes componentes, como la
descomposición de problemas, el reconocimiento de patrones, la abstracción y el
diseño de algoritmos. Vamos a aplicar paso a paso estos componentes en dos contextos
distintos: programación tradicional y aprendizaje automático.
PROGRAMACIÓN
TRADICIONAL:
1.
Descomposición de problemas:
Identifica un problema específico en el ámbito de la
educación superior que pueda ser abordado mediante programación tradicional.
Por ejemplo, podríamos querer diseñar un sistema simple de gestión de
calificaciones.
2.
Reconocimiento de patrones:
Identifica patrones y relaciones en el problema. En el
caso del sistema de gestión de calificaciones, los patrones pueden incluir la
entrada de calificaciones, el cálculo del promedio, y la determinación de si un
estudiante pasa o no.
3.
Abstracción:
Abstrae los elementos esenciales del problema y
simplifica su representación. Define las operaciones básicas, como la entrada
de calificaciones, la realización de cálculos y la generación de resultados.
4.
Diseño de algoritmos:
Crea algoritmos paso a paso para resolver cada parte del
problema. Por ejemplo, podrías diseñar un algoritmo para calcular el promedio
de calificaciones y otro para determinar si un estudiante pasa o no.
5.
Programación:
Implementa el algoritmo en un lenguaje de programación,
como Python. Aquí hay un ejemplo muy básico en Python para calcular el
promedio:
Esta es mi interacción con google colab
El promedio es: 86.6
APRENDIZAJE AUTOMÁTICO:
1. Identificar el problema:
Elige un problema adecuado
para el aprendizaje automático en el contexto de la educación superior, como
predecir el rendimiento de los estudiantes en función de ciertas variables.
2. Recopilar datos:
Obtén datos relevantes para
entrenar y evaluar el modelo. Por ejemplo, podrías recopilar datos históricos
de calificaciones, horas de estudio, y participación en clases.
3. Seleccionar un modelo:
Elige un modelo de
aprendizaje automático apropiado para tu problema. Podrías optar por un modelo
de regresión para predecir calificaciones.
4. Entrenar el modelo:
Divide tus datos en
conjuntos de entrenamiento y prueba, y entrena el modelo utilizando algoritmos
de aprendizaje automático.
5.
Evaluar el modelo:
Evalúa el rendimiento del
modelo utilizando datos de prueba y ajusta los parámetros según sea necesario.
6.
Utilizar el modelo:
Cuando el modelo sea satisfactorio, puedes usarlo para
predecir el rendimiento de nuevos estudiantes en función de las variables
seleccionadas.
Estos son pasos básicos y
simplificados. En la práctica, cada uno de estos pasos puede ser más complejo y
requerir un análisis detallado del problema y de los datos disponibles.
Vamos a abordar un problema
de optimización paso a paso utilizando ambos enfoques: la programación
tradicional y el aprendizaje automático. Supongamos que queremos asignar cursos
a estudiantes de manera óptima para maximizar la satisfacción estudiantil. Este
es un problema típico en el ámbito de la educación superior.
PROGRAMACIÓN
TRADICIONAL:
1. Descomposición de
problemas:
Identifica los componentes
esenciales del problema, como la lista de estudiantes, la lista de cursos
disponibles y los criterios de asignación.
2.
Reconocimiento de patrones:
Identifica patrones en los datos, como las preferencias
de los estudiantes y los requisitos de los cursos.
3.
Abstracción:
Abstrae los elementos esenciales del problema, como la
función de asignación de cursos que maximiza la satisfacción estudiantil.
4.
Diseño de algoritmos:
Crea algoritmos para la
asignación óptima de cursos. Puede ser un algoritmo de búsqueda exhaustiva,
algoritmo voraz, o algún otro algoritmo de optimización.
5.
Programación:
Ejemplo básico utilizando un algoritmo voraz en Python:
Esta es mi interacción con google colab

Ejemplo
de Visualización para Programación Tradicional:´
Esta es mi interacción con google colab.


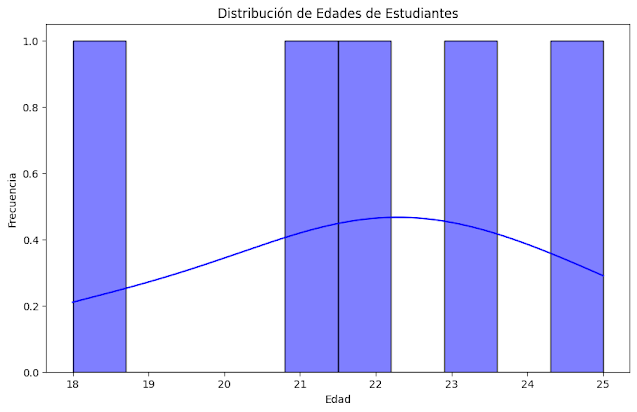
Esta gráfica muestra un modelo de regresión lineal que predice las calificaciones de los estudiantes.
Puedes adaptar esto según la complejidad y naturaleza de tu modelo de aprendizaje automático real.
Dado que los ejemplos que te proporcioné son bastante abstractos y no incluyen datos específicos ni modelos de aprendizaje automático, es difícil proporcionar gráficos específicos. Sin embargo, puedo mostrarte cómo podrías visualizar algunos aspectos de estos problemas. Utilizaré un ejemplo más simple para ilustrar.
Ejemplo de Visualización para Programación Tradicional:
Esta es mi interacción con google colab.
.png)
Esta gráfica de barras muestra las preferencias de los estudiantes por cada curso. Puedes adaptar esto a tu problema real con datos específicos.
Ejemplo de Visualización para Aprendizaje Automático:
Esta es mi interacción con google colab.
Dado que la visualización de un modelo de aprendizaje automático puede variar según el tipo de modelo, aquí hay un ejemplo simple utilizando un modelo de regresión lineal en un contexto bidimensional:
.png)
Esta gráfica muestra un modelo de regresión lineal que predice las calificaciones de los estudiantes. Puedes adaptar esto según la complejidad y naturaleza de tu modelo de aprendizaje automático real.
Ten en cuenta que estos son solo ejemplos simplificados y necesitarás adaptarlos a tus datos específicos y al tipo de visualización que sea más relevante para tu problema.
Ejemplo para reflejar la asignación de 50 estudiantes a 5 cursos
ficticios de anatomía. Primero, mostraré cómo podrías visualizar las
preferencias de los estudiantes por los cursos.
Esta es mi interacción con google colab.
.png)
Ahora, para la programación tradicional de asignación de cursos, podríamos utilizar un enfoque simple
como el algoritmo voraz que mencioné anteriormente.
Dado que estos datos son ficticios, podemos hacer una asignación básica.
Esta es mi interacción con google colab.
.png)
En este caso, he asignado a cada estudiante al curso de anatomía de manera secuencial.
Estos son ejemplos básicos.
Conclusiones y reflexiones: La aplicación de los componentes del pensamiento
computacional con Python en la educación superior facilita un aprendizaje más completo
y prepara a los estudiantes para enfrentar desafíos complejos en sus futuras carreras
profesionales.
.png)
.png)

Comentarios
Publicar un comentario